仮名処理は、個人情報保護法や守秘義務の問題を一気に解決する方法ではありません。
それでも、クラウドAIに生の依頼者情報や事件情報をそのまま入れないという意味で、実務上のリスク低減策として検討する価値があります。
本記事では、仮名処理の法的な位置づけと、実務上の現実的なやり方をあわせて整理します。
1. 仮名処理だけで法的問題が消えるわけではない
結論から言うと、仮名処理だけで個人情報保護法や守秘義務の問題が解消するとは限りません。
ここで言う「仮名処理」とは、氏名や当事者名等を A、B社などの記号に置き換える実務上の処理を指します。これは個人情報保護法上の「仮名加工情報」(法41条以下)と重なる場合もありますが、常に同義ではありません。
個人情報保護法における「個人情報」の定義は広く、氏名や住所だけではありません。事件の具体的な経緯、日付、金額、関係者の属性、職業といった情報の組み合わせによっても特定の個人を識別できる場合があります。その場合、氏名を A に置き換えていても個人情報に当たり得ます。
また、自分の手元に「A=山田太郎」のような対応表や元データがある限り、置き換え後のデータも自分にとっては容易照合可能であり、個人情報のままです。
したがって、仮名処理は免責装置ではなく、仮名処理をしたから個人情報保護法や守秘義務の問題が消えると考えるのは危険です。
この点は、個人情報の記事で紹介した日本弁護士連合会「弁護士業務における生成AIの利活用等に関する注意事項」(2026年2月1日)にも表れています。同資料の注記15では、「例えば、企業の営業秘密など、企業名が特定されなくとも、漏えいしてはならない情報があり、そうした情報については、匿名化をするだけでなく、漏えいしても問題とならない程度に抽象的なものとするなど、情報内容を加工することが求められる。」とされています。つまり、氏名や企業名を置き換えただけでは足りず、内容それ自体が秘匿性を持つ場合には、仮名処理だけで守秘義務上の問題がクリアできるわけではないということです。
2. それでも仮名処理を検討する意味はある
もっとも、仮名処理には実務上も法的にも意味があります。
実際、上記「弁護士業務における生成AIの利活用等に関する注意事項」でも、生成AIの利用方法として「③適切な匿名化・抽象化を施す、あるいは一般化した範囲での利用」が推奨されています。したがって、仮名処理や抽象化は万能ではないものの、何もしないより一段安全な利用方法として位置づけられているといえます。
対応表を AI に渡さず、文章の内容からも本人が推知できない状態にしておけば、受託先である AI 事業者にとっては個人情報に当たらない可能性があります。また、万一の漏えい時にも、識別可能性が低ければ実害のリスクを下げられます。
入力内容によっては、仮名処理を施すことで個人情報に該当しなくなる場合もあります。たとえば、一般的な法律論の検討で、当事者の氏名や社名を A氏・B社に置き換えれば、残りの情報だけでは個人を識別できないケースは十分にあり得ます。
したがって、仮名処理は万能ではないものの、クラウドAIに生データをそのまま入れないための現実的なリスク低減策として、検討する意味があります。
3. 現実的なやり方は、ローカルAIで先に仮名処理すること
クラウドAIは非常に便利ですが、DPA のあるビジネスプランを利用していても、「依頼者情報をそのままクラウドに入れるのはやはり不安だ」と感じる場面はあります。
そのようなときの現実的な方法の一つが、クラウドAIにデータ送信する前に、まずローカルで動くAIに仮名処理をさせるという運用です。
たとえば、氏名を「A」「B」、法律事務所名を「C事務所」、会社名を「D社」といった形に置き換えたうえで、匿名化後の文章だけをクラウドAIに渡す、という流れです。もちろん、ローカルAIによる匿名化も万能ではなく、最終確認は必要です。しかし、「生の固有名詞や連絡先をそのままクラウドに送らない」というだけでも、心理的・実務的なハードルはかなり下がります。
なお、匿名化を自分で手作業でする、という方法も考えられます。ただ、せっかく業務の効率化のために AI を使おうとしているのに、その前段階の匿名化作業に毎回かなりの時間をかけるのでは本末転倒になりかねません。その意味でも、まずローカルAIで仮名処理をしてからクラウドAIに渡すという流れには、実務上の意味があります。
4. LM Studioとは何か
こうした用途で試しやすいのが、LM Studio というアプリです。
LM Studio は、PC にダウンロードした AI モデルを、その PC 上で動かして使うためのアプリです。公式サイトでは、ローカルかつプライベートに AI モデルを動かせることが案内されており、Windows・macOS・Linux 向けのダウンロードも用意されています。
また、LM Studio の公式ドキュメントでは、モデルをダウンロードした後のチャットや文書処理はオフラインで行うことができ、入力内容は端末外に出ないと案内されています。他方で、モデル検索やモデルダウンロード、アプリ更新確認の場面では通信が発生するとも明記されています。したがって、「常時完全に通信しないアプリ」というより、ダウンロード後の通常利用はローカルで完結できるアプリと理解するのが正確です。
5. 最初に試すモデルは Gemma 3 4B で十分
ローカルLLMにはいろいろなモデルがありますが、最初は迷いやすいところです。実際に試してみると、モデルによって日本語の安定性や匿名化の精度、処理速度にかなり差があります。
その点、最初にLM Studioがダウンロードを勧めてくる Gemma 3 4B を、そのまま試すので十分です。少なくとも、「ローカルで仮名処理を試す」という目的から出発するのであれば、最初の選択として無難です。
5-1. 最初のモデル選択画面では、このボタンを押す
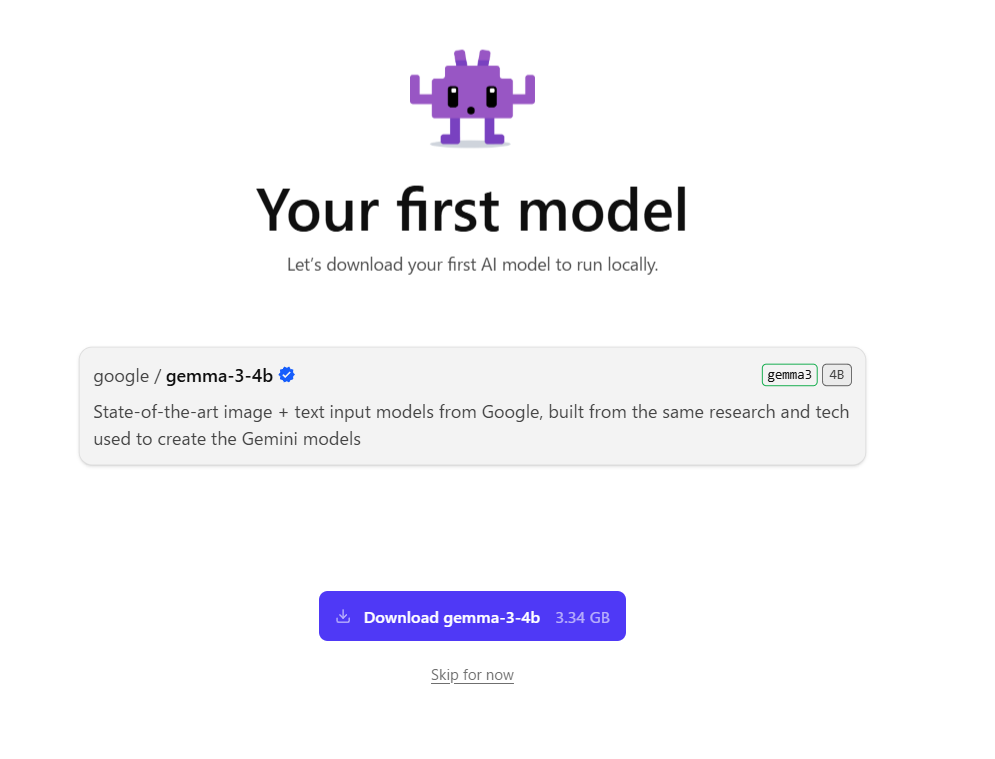
この画面では、Download gemma-3-4b のボタンを押せば大丈夫です。
最初は他のモデルを探し回らなくても構いません。まずは、LM Studio が最初に提示する Gemma 3 4B を入れて動かしてみるのが分かりやすいです。
6. 初期設定画面ではどうするか
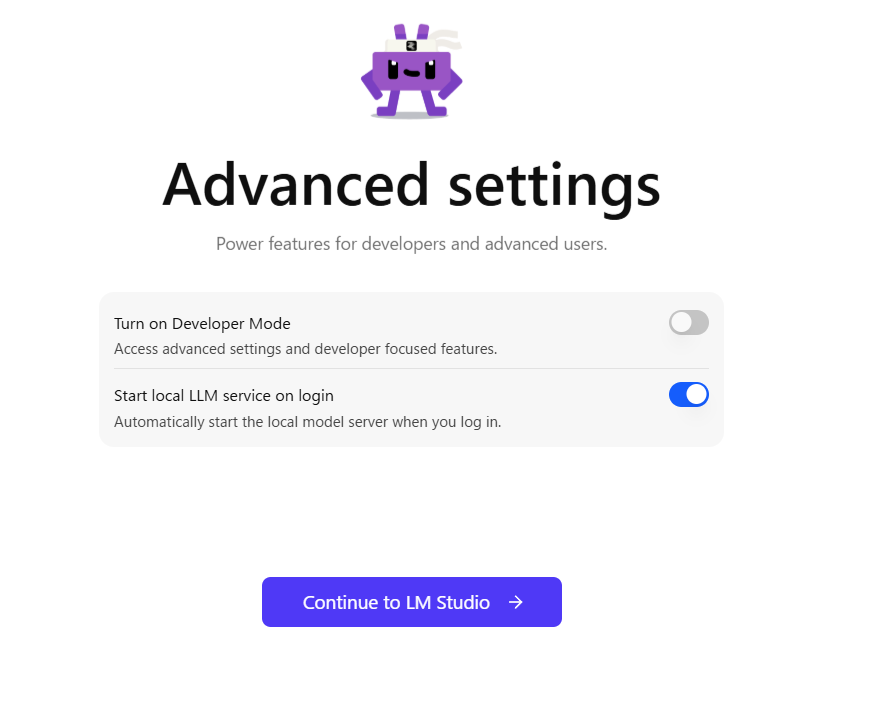
ここでは、次の設定を勧めます。
- Turn on Developer Mode:オフのまま
- Start local LLM service on login:オフ推奨
Turn on Developer Mode はオフのままでよい
この項目は、名前のとおり開発者向け、上級者向けの設定です。最初にローカルAIを試す段階では不要です。オンにすると設定項目が増え、かえって分かりにくくなります。まずは オフのまま で十分です。
Start local LLM service on login はオフ推奨
この項目は、Windows にログインした時点で LM Studio のローカルサービスを自動起動する設定です。常時使うのであれば便利なこともありますが、通常はそこまで必要ありません。オンにすると、PC 起動時から関連サービスが立ち上がるため、メモリや CPU を余分に使う可能性があります。
したがって、少なくとも最初のうちは、LM Studioを使うときだけ起動する運用で十分です。その意味で、オフ推奨です。
7. 新規チャット開始時は「Load Model」を押す
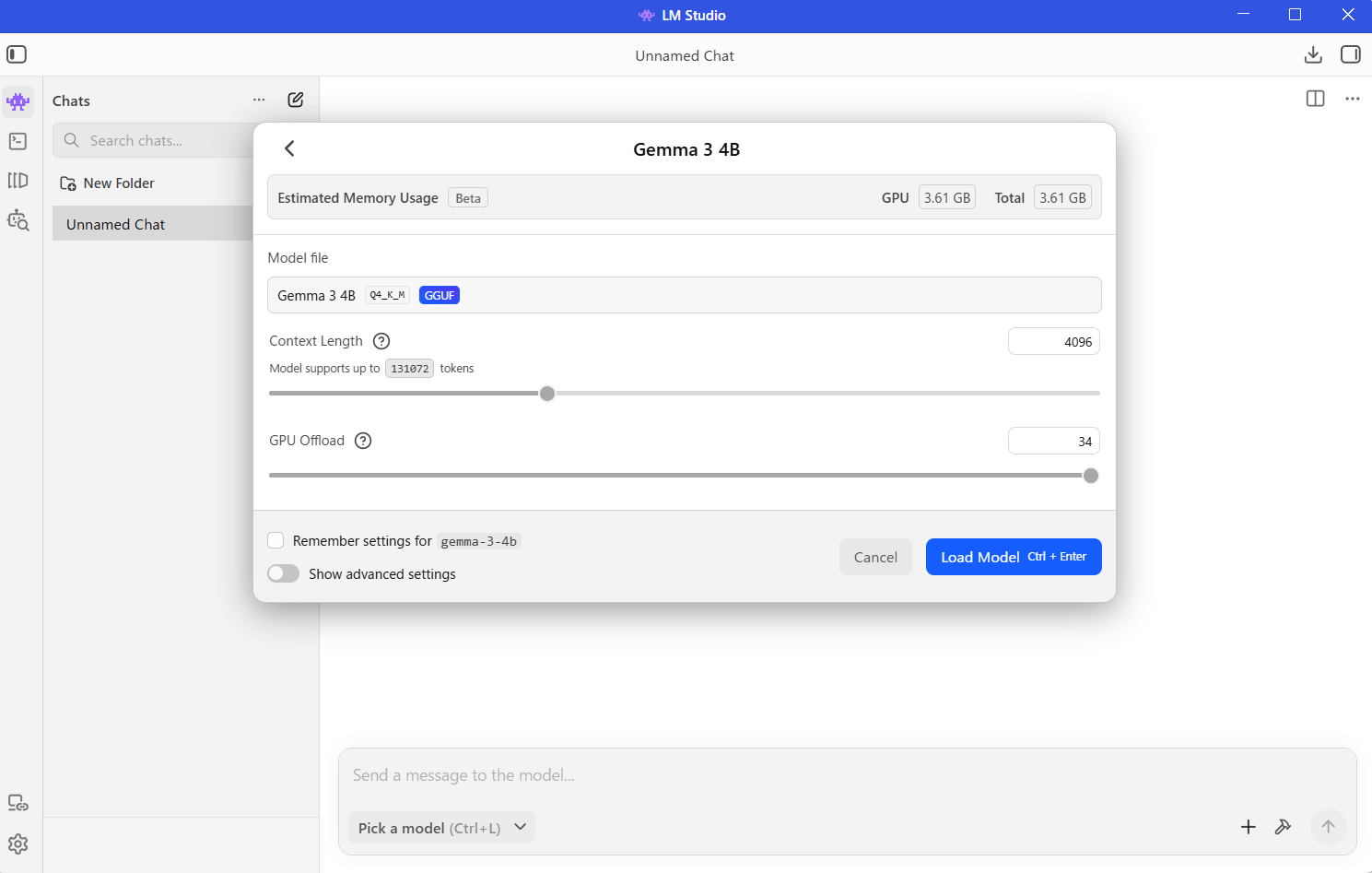
モデルをダウンロードした後、新規チャットを開くと、このような画面になります。ここでは、Load Model を押してください。ダウンロード済みであっても、そのモデルがまだ今のチャットに読み込まれていないためです。
「モデルを入れたのにすぐ話せないのか」と感じるかもしれませんが、ここで Load Model を押すことで、そのチャットで Gemma 3 4B が使える状態になります。
つまり、
- ダウンロード済みであること
- そのチャットにロード済みであること
は別です。新規チャットの開始時には、まず Load Model を押す、と覚えておけば十分です。
8. 実際の使い方
LM Studio で Gemma 3 4B を読み込んだら、チャット欄に匿名化用のプロンプトを貼り付け、その下に匿名化したい文章を入れて実行します。
なお、GPU を搭載していない PC だと、処理にはかなり時間がかかることがあります。GPU とは、もともとは画像・映像処理のためのパーツですが、AI のように大量の計算をまとめて高速に処理するのが得意なため、ローカルLLMの速度にも大きく影響します。GPU がない PC では CPU だけで処理することになり、文章量によっては、匿名化の出力が返ってくるまでかなり待つことがあります。
実務上は、匿名化後の本文だけをクラウドAIに渡し、対応表はローカル確認用にとどめるのが無難です。対応表には元の氏名や法人名がそのまま載るため、それ自体が高い秘匿性を持つ情報だからです。
大まかな流れとしては、次のように考えると分かりやすいです。
- LM Studio でローカルモデルを用意する
- 仮名処理用のプロンプトを貼る
- 匿名化したい文章を入力する
- 出力された本文と対応表を確認する
- クラウドAIには匿名化後の本文だけを渡す
- 対応表はローカル側に残す
9. 匿名化用プロンプトの例
#指示
以下の文章について、個人情報や法人情報が含まれていれば、匿名化してください。
匿名化のルール
- 個人名は「A」「B」「C」…に置き換える
- 法人名・団体名・事務所名・病院名・学校名・官公署名などは「A社」「B社」「C事務所」「D病院」「E校」「F庁」など、属性が分かる形で置き換える
- 相手方本人、原告、被告、申立人、担当者、医師、弁護士など、役割が重要な場合は、役割が分かる表現を優先する
例:「A(原告)」「B弁護士」「C医師」「D社担当者」
- 同一人物・同一法人は、文中で必ず同じ記号に統一する
- 法人と個人が混同しないようにする
- 住所、電話番号、メールアドレス、生年月日、社員番号、口座番号、登録番号、車両番号、学校名、支店名、施設名、商品名その他特定につながる情報も、必要に応じて一般化または伏せ字化する
- 日付、金額、時系列、法律上重要な事実関係は、私が明示的に求めない限り変更しない
- 匿名化後も、文章の意味、立場関係、因果関係が分かるように保つ
- 匿名化した結果が不自然になる場合は、読みやすさを優先して適切に一般化する
出力ルール
- まず匿名化後の本文を示す
- 次に対応表(例:A=○○、B社=○○株式会社)を別に示す
#文章
10. 注意点
仮名処理には、次のような限界があります。
- 固有名詞の見落とし
- 肩書や地名からの再識別
- 元の意味関係が崩れるリスク
また、ローカルLLMによる匿名化も万能ではありません。表記ゆれや文脈依存の判断ミスは残り得ます。したがって、最終的には人の目で確認することが前提です。
まとめ
仮名処理は、個人情報保護法や守秘義務の問題を一気に解決する方法ではありません。
それでも、
- クラウドAIへ生データをそのまま送らない
- 対応表をローカルに残す
- 最後に人が全文確認する
という運用を組み合わせれば、実務上のリスクをかなり下げられます。
その意味で、仮名処理は「完全な解決策」ではなく、現実的で有効な安全策の一つとして位置づけるのがよいと思います。